- 缓存解析
缓存解析
缓存解析是 sbt 从 0.13.7 版本开始添加的**实验性**功能,用于解决依赖解析的扩展性性能问题。
设置
要设置缓存解析,请在项目的构建中包含以下设置
updateOptions := updateOptions.value.withCachedResolution(true)
依赖项作为图
项目使用libraryDependencies设置声明自己的库依赖项。您添加的库也会引入它们的传递依赖项。例如,您的项目可能依赖于 dispatch-core 0.11.2;dispatch-core 0.11.2 依赖于 async-http-client 1.8.10;async-http-client 1.8.10 依赖于 netty 3.9.2.Final,等等。如果我们将每个库视为一个节点,并且箭头指向依赖节点,那么我们可以将整个依赖项视为一个图 - 特别是 有向无环图。
这种图状结构(源自 Apache Ivy)允许我们 在传递依赖项中定义覆盖规则和排除规则,但随着节点数量的增加,解析依赖项所需的时间会显着增加。有关完整说明,请参阅本页后面的 动机 部分。
缓存解析
缓存解析功能类似于增量编译,它只重新编译自上次compile以来已更改的源代码。与 Scala 编译器不同,Ivy 没有单独编译的概念,因此需要实现它。
缓存解析功能不会解析完整的依赖项图,而是创建微图 - 每个直接依赖项在所有相关子项目中出现一个。这些微图使用 Ivy 的解析引擎进行解析,结果存储在本地 $HOME/.sbt/1.0/dependency/(或由 sbt.dependency.base 标记指定)下,在所有构建中共享。在所有微图解析完成后,它们会通过应用冲突解析算法(通常选择最新版本)拼接在一起。
当您将新库添加到项目中时,缓存解析功能将检查 $HOME/.sbt/1.0/dependency/ 下的微图文件并加载先前解析的节点,这会产生可忽略的 I/O 开销,并且只解析新添加的库。预期的性能改进是,第二个和第三个子项目可以利用第一个子项目中解析的微图,避免重复的工作。下图说明了项目 A、B 和 C,它们都命中同一组 json 文件。
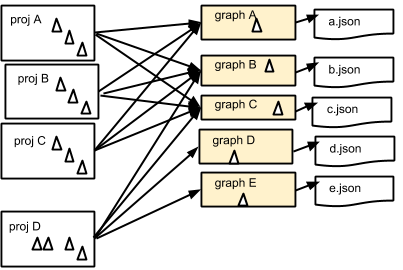
实际的加速将因情况而异,但如果您有许多子项目,您应该会看到显着的加速。来自用户的初步报告显示,时间从 260 秒变成了 25 秒。您的实际情况可能会有所不同。
注意事项和已知问题
缓存解析是**实验性**功能,您可能会遇到一些问题。如果您遇到问题,请向 GitHub Issue 或 sbt-dev 列表报告。
首次运行
您第一次运行时,缓存解析可能很慢,因为它需要解析所有微图并将结果保存到文件系统中。每当您添加系统以前从未见过的节点时,它都会保存微图。从第二次运行开始,速度应该会更快,但将完整解析的update与第二次运行进行比较可能并不公平。
Ivy 忠实度不能保证
Ivy 的一些行为没有意义,尤其是在 Maven 模拟方面。例如,它似乎将 Maven 发布库引入的所有传递依赖项视为force(),即使原始的pom.xml没有说明。
$ cat ~/.ivy2/cache/com.ning/async-http-client/ivy-1.8.10.xml | grep netty
<dependency org="io.netty" name="netty" rev="3.9.2.Final" force="true" conf="compile->compile(*),master(*);runtime->runtime(*)"/>
在对同一个库使用不同Maven 分类器的多依赖项方面也存在一些问题。在这些情况下,再现与正常update完全相同的结果可能没有意义,或者根本不可能。
SNAPSHOT 和动态依赖项
当微图包含 SNAPSHOT 或动态依赖项时,该图被视为动态图,并且将在执行单个任务后失效。因此,如果您的图中存在任何 SNAPSHOT,您的体验可能会下降。(这将来可能会得到改善)
一个名为updateOptions的设置键使用update任务定制了托管依赖项解析的详细信息。它的一个标记称为latestSnapshots,它控制链式解析器的行为。直到 0.13.6 版本,sbt 一直在链中选择它找到的第一个-SNAPSHOT修订版。当latestSnapshots启用(默认值:true)时,它将查看链上的所有解析器,并使用发布日期进行比较。
权衡可能是,如果您在构建中有很多远程仓库,或者您距离服务器很远,解析时间可能会更长。因此,以下是禁用它的方法
updateOptions := updateOptions.value.withLatestSnapshots(false)
动机
sbt 在内部使用 Apache Ivy 来解析库依赖项。尽管 sbt 这些年来一直得益于不必重新发明自己的依赖项解析引擎,但我们越来越发现扩展性挑战,尤其是在具有多个子项目和大型依赖项图的项目中。sbt 的解析可扩展性涉及几个因素
- 图中的传递节点(库)数量
- 排除和覆盖规则
- 子项目数量
- 配置
- 仓库数量及其可用性
- 分类器(IDE 使用的附加源代码和文档)
在上述因素中,对性能影响最大的是传递节点的数量。
- 节点越多,版本冲突的可能性就越大。冲突通常通过选择同一库中最新版本来解决。
- 节点越多,就需要进行更多回溯以检查排除和覆盖规则。
排除和覆盖规则在传递依赖项中应用,因此每当将新节点引入图时,它都需要检查其父节点的规则、祖父母节点的规则、曾祖父母节点的规则等等。
sbt 将配置和子项目视为独立的依赖项图。这使我们能够为不同的配置和子项目包含任意库,但是如果依赖项解析很慢,线性缩放就开始影响性能。之前曾尝试缓存库依赖项的结果,但当libraryDependencies发生变化时,它仍然会导致完全解析。
